Rule-Based Alerts Configurations
Alerting - Common Use Cases and Examples
This section explains common use cases encountered in configuring alert rules.
Alert Configuration with Multiple Rules
Users often want to create alert rules with multiple related conditions to ensure more meaningful and actionable notifications.
For instance, instead of having separate alerts for server resource usage and application service turnaround time, it's more effective to trigger an alert when both conditions are met. Here's how to set up such an alert rule:
- Condition 1: Check for CPU Usage and Memory Usage (Server Resource Usage Data Model).
- Condition 2: Check for Service Requests Turnaround Time (TAT Data Model).
The Server Resource Usage DM used for Condition 1 can include multiple metrics that monitor various health parameters like CPU usage, memory usage, disk I/O, etc. This way, you can create comprehensive alerts that take multiple factors into account.

The default system behavior is to generate notifications when both conditions are met R1 and R2. If you prefer to trigger an alert when either the turnaround time is high or server resource usage is high, you can configure an OR condition R1 or R2 in the evaluation script.
This way, an alert generated for this rule will list the individual condition metrics and their interpretation.
Alert When Any or All Of The Conditions Turn True
In a default alert rule with multiple conditions, the system generates alerts when all conditions are met (e.g., R1 and R2 and R3 and R4). If you want the system to trigger an alert when any of the conditions are true, you can configure the evaluation script with an OR condition, like R1 or R2 or R3 or R4.
You can also create custom evaluation logic by adjusting the evaluation script formula. For example, R1 and (R2 or R3) and not R4 would generate an alert if R1 is true and either R2 or R3 is true, but R4 is not true.
Tracking State Changes Along With Other Conditions
In this example, suppose you want notifications when either the connectivity status is "Down" or the connectivity latency exceeds 100 ms.
To achieve this, you would create two conditions: one using the Data Model for connectivity status and another for the Data Model for latency. The default behavior would be to generate alerts when both conditions are met.
To make the system trigger an alert when either condition is true, you can adjust the evaluation script to use an OR condition, like R1 or R2. This way, you'll receive notifications when either of the specified conditions is met.
Users Interested Only in Down Event Notification
If you're only interested in receiving notifications when a component's state changes to an undesired state, you can disable the alarm mode in the rule configuration. For instance, if you want to be notified only when the connectivity status changes to "Down," you can achieve this by disabling the alarm mode in the rule.
Once alarm mode is disabled, the system will generate notifications at regular intervals (by default, every 5 minutes) as long as the connectivity status is Down.
Throttling can be enabled if the frequency of updates is to be changed. Please note that there will be no clear alarm generated and if the condition clears, it will just stop generating notifications..

Summarized Notifications
In cases where vuSmartMaps is used to monitor the success rate of various transactions in an E-commerce application, and you want to receive notifications when the success rate of any transaction type falls below 85%, you can configure summarized notifications.
This will help you get a comprehensive alert when multiple related conditions occur.
| Transaction Type | Success Rate | Action Required |
|---|---|---|
| Login | 92% | No Action |
| Checkout | 81% | Alarm |
| Payment | 76% | Alarm |
| Search | 93% | No Action |
| User Settings | 95% | No Action |
| Review | 87% | No Action |
Instead of receiving individual notifications for each transaction type, you can configure a consolidated notification that includes details of all transaction types with low success rates. This can be done by adjusting the notification level in the advanced configuration settings.

Some transaction types are experiencing lower success rates than usual. Here are the current success rates for each transaction type:
| Transaction Type | Success Rate |
|---|---|
| Login | 92% |
| Checkout | 81% |
| Payment | 76% |
| Search | 93% |
| User Settings | 95% |
| Review | 87% |
Adding Contextual Information
To provide additional information in alert notifications, such as a list of the top processes consuming CPU when receiving a high CPU usage alert, you can utilize information rules. Please check the Information Rules section for more details.
Remove Metric From Contextual Information Of An Alert.
When you have multiple rules specified in an alert configuration, the results from each rule will typically be included in the alert notification.
However, there are situations where you might want to exclude results from some rules in the notification.
For instance, if you have an alert rule checking for low transaction volume and another condition for stream processing lag (Kafka), you might want to generate alerts for low transaction volume only when Kafka lag is below a certain threshold. This can be achieved through Evaluation Script settings.
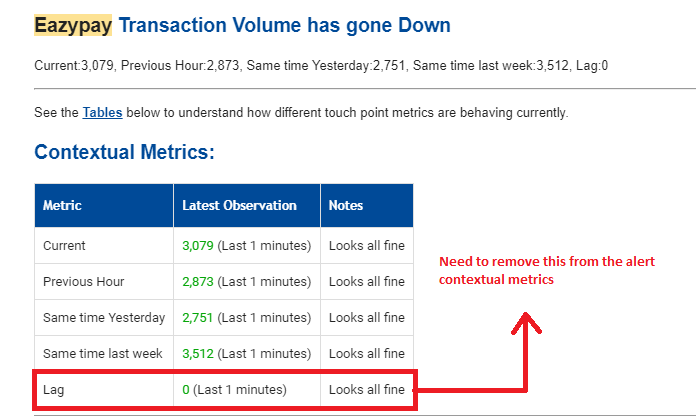
You can accomplish this by clearing the entire rule dictionary for a specific rule from the D array after performing the necessary operation. In this example, we've added the lag Data Model as R2. This helps customize the alert notifications to include only the relevant information you want to see.
if R1 and R2:
D[1]['Eazypay Lag - Alert'] = {} #empty the R2 from D Array
RESULT = True
Sending Periodic Updates If The Alarm Condition Persists
You can send periodic updates when the alarm condition persists for an extended time by configuring specific channels for these reminders.
In the advanced configuration settings, you'll find separate options for each channel where you want to send these updates. This feature helps keep operators informed with regular reminders when an alarm condition remains active for a prolonged duration.
| Channel | Configuration |
|---|---|
| Email Channel | EmailAlerterUpdate |
| SMS Channel | SmsAlerterUpdate |
| WhatsApp Channel | WhatsappAlerterUpdate |
| Microsoft Teams Update | TeamsAlerterUpdate |
| Slack Channel Update | SlackAlerterUpdate |
For example, if update notification emails are required every 30 minutes if the alarm condition persists, the following configuration is to be specified in Advanced Configuration.
EmailAlerterUpdate: 30
The above configuration would result in periodic updates every 30 minutes if the alarm is active.
Sending a Trigger Update on Email, SMS, WhatsApp, Slack, and Teams
In alarm mode, email notifications are sent when the alarm becomes active and when it gets cleared. Additionally, an update notification email is sent when the alarm's severity changes to keep operators informed. But in some cases, you might want to send an update notification when specific conditions are met.
For example, you can configure an update notification email to be sent when the transaction count exceeds a certain threshold beyond what's specified in the alert rule.
This allows for more customized notifications when certain criteria are fulfilled. This can be done using the force_upate flag and can be seen in the following example.
If R1:
# Alert is active based on the threshold configured in the rule
vol = get_vumetric_value(D, 1, ‘success_rate’)
If vol > 100000:
META_DATA[‘force_update] = True
Escalation Matrix
In alarm mode, email notifications are sent when the alarm becomes active, and again when it's cleared.
These notifications also update when the alarm's severity changes. However, there are situations where you might want to escalate notifications if the alarm condition remains active for an extended period.
The example below demonstrates an evaluation script that sends an escalation email notification to one email group after 2 hours of alarm activation and another escalation email to a different group if the alarm persists for over 6 hours.
This way, you can implement multi-tiered escalation strategies for critical alerts.
if R1:
# alarm is to be marked as active
RESULT = True
duration = META_DATA.get('’duration’, 0)
cur_time = datetime.datetime.now(datetime.timezone.utc)
last_email_update = (cur_time - META_DATA.get('EmailAlerter_last_update’, cur_time)).total_seconds()
if duration >= (2*60*60) and duration <= (6*60*60) and last_email_update > (1*60*60):
# If the alarm has been active for more than 2 hours and we have
# not sent an email update recently
ALERT_CHANNELS.append('alertByEmail')
EMAIL_GROUP_LIST = ['group1']
# Force update.
META_DATA['force_update'] = True
elif duration > (6*60*60) and last_email_update > (3*60*60):
# If the alarm has been active for more than 6 hours and we have
# not sent an email update recently
ALERT_CHANNELS.append('alertByEmail')
EMAIL_GROUP_LIST = ['group2']
META_DATA['force_update'] = True
Avoiding Alarm Clear Notification on Certain Channels
In alarm mode, the system sends email notifications when the alarm activates and when it's cleared. However, there are instances where operators don't want to receive clear notifications via email, SMS, or WhatsApp.
You can configure this by adjusting the settings in the Advanced Configuration.
This allows you to choose specific channels for which you want to avoid clear notifications, giving you more control over the alerts you receive.
| Channel | Configuration |
|---|---|
| Email Channel | EmailAlerterClear |
| SMS Channel | SmsAlerterClear |
| WhatsApp Channel | WhatsappAlerterClear |
For example, if clear notification emails are not required over email, the following configuration is to be specified in Advanced Configuration.
EmailAlerterClear: false
It should be noted that the default value of this configuration is true.
Rules with Different Grouping Levels
Consider the E-Com application which has application nodes running on 4 systems. Let us consider a case where an alert notification is to be generated if the total success rate for transactions of the Ecom application is below 85% or the success rate of transactions handled by individual application nodes is below 85%.
The alert rule for this requirement will use two conditions with two separate Data Models.
Rule 1 ⇒ Total number of transactions with a threshold of> 85%(No grouping)
Rule 2 ⇒ Total number of transactions with a threshold of> 85% (Grouped by application node name)
By default, the system considers the largest grouping level in the conditions as the grouping level at which notifications are to be generated. Hence, in the above example, notifications will be generated for each server separately.
If the requirement is to have the alert generated at an aggregate level, then notification_level settings in advanced configuration can be used to have the notification generated at the 0th level. i.e without any grouping.

State Alarm Clear Controls
There are a few conditions in which an alarm can get stale, such as if we are not getting data for a bucket (this can happen due to some genuine issue on the target side, or some data store issues because of which we are not able to get data into ES or not able to query ES) whose alarm has already been generated but not cleared yet, that alarm will stop updating and will not clear as well. Such an alarm is called a stale alarm.
There is a default cleanup for such stale alarms which will happen after 24 hours, i.e., If we do not get the data for a bucket for 24 hours, we will clear the stale alarm.
If required this clean-up duration can be reduced or increased as per the requirement for each alert rule, using advanced configuration.
In the advanced configuration of alerts, there is a setting available where we can set up the stale alarms' clear duration. This is in minutes. Stale alarms will clear after the time configured here.

